
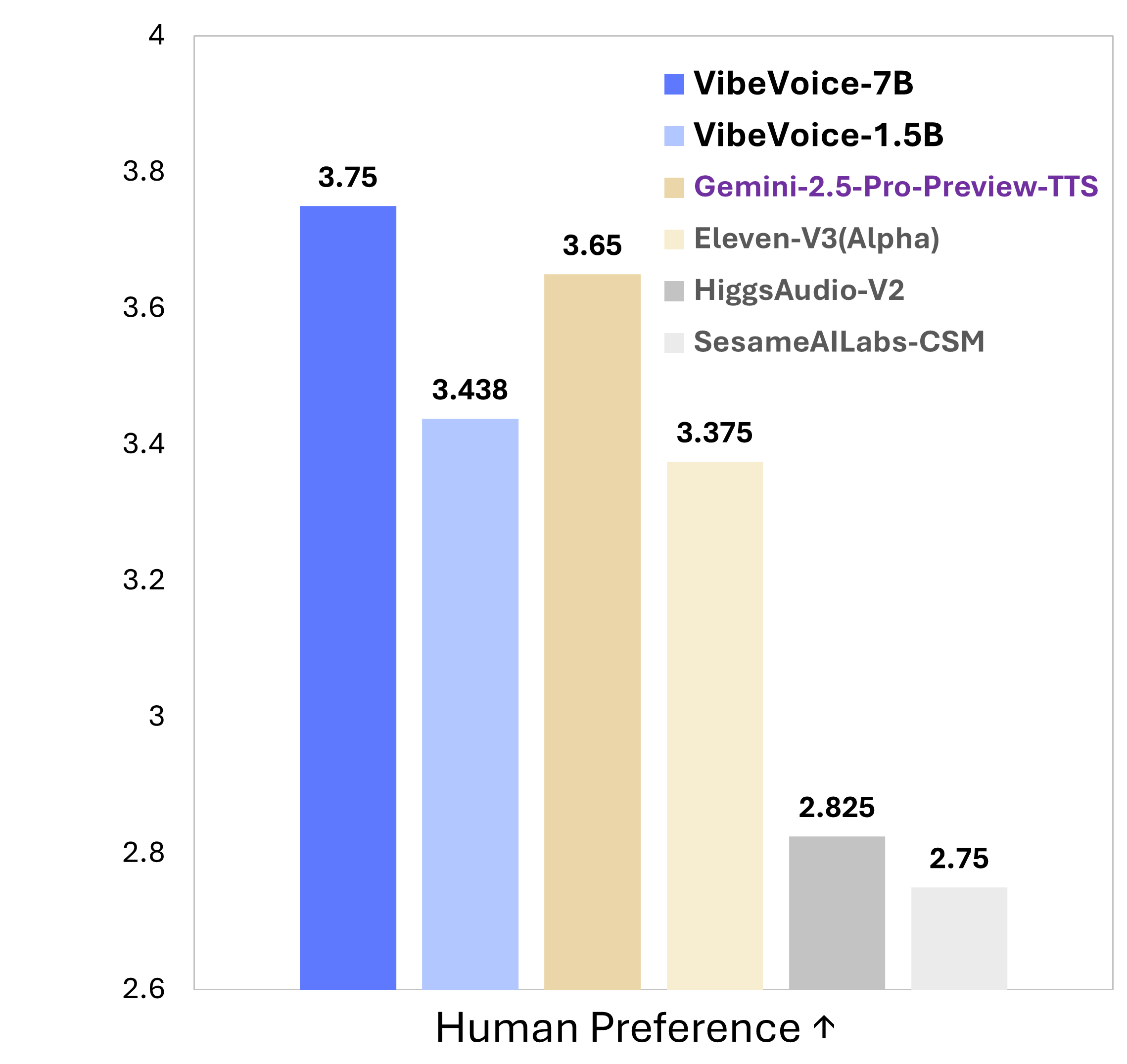
O VibeVoice é um novo modelo de código aberto que se destaca na geração de áudio conversacional expressivo e de longa duração, como podcasts, a partir de texto. Este sistema busca resolver problemas significativos enfrentados por soluções tradicionais de Texto para Fala (TTS), especialmente nas áreas de escalabilidade, consistência entre os falantes e naturalidade nas trocas de fala.
Uma das inovações centrais do VibeVoice é a implementação de tokenizadores de fala contínua, tanto acústicos quanto semânticos, que operam em uma taxa ultra-baixa de 7,5 Hz. Essa abordagem permite preservar a fidelidade do áudio de forma eficiente, ao mesmo tempo em que aumenta consideravelmente a eficiência computacional ao processar sequências longas.
Além disso, o VibeVoice utiliza um framework de difusão de próximo token, que se aproveita de um Modelo de Linguagem de Grande Escala (LLM) para compreender o contexto textual e o fluxo do diálogo, e uma cabeça de difusão para gerar detalhes acústicos de alta fidelidade. O modelo tem a capacidade de sintetizar discursos com até 90 minutos de duração, podendo incluir até 4 falantes distintos, superando as limitações de 1 a 2 falantes comuns em muitos modelos anteriores.



Confira os últimos vídeos publicados no canal

A maior virada da Inteligência Artificial começou... e vem da China

o ALERTA de Satya Nadella que ASSUSTOU o mercado de IA

GPT 5.6 SURPREENDE: OpenAI finalmente alcançou a Anthropic?

Os novos modelos de IA estão decepcionando... e ninguém quer admitir isso

Midjourney quer ESCANEAR humanos e o Open Source já rivaliza com Claude Opus

Rio 3.5 e Fable 5: as duas polêmicas que expõem o futuro da IA

Fim dos PCs como conhecemos: Nvidia, Microsoft e IA local vão mudar tudo

O plano SECRETO das Big Techs para cobrar MUITO mais pela IA

BOLHA da IA ou NOVA era de crescimento EXPONENCIAL? O mercado está dividido

Nova IA da OpenAI traduz em TEMPO REAL e pode mudar o mundo dos negócios

Spec Driven Development (SDD): a habilidade que vai separar quem SOBREVIVE à IA

DeepSeek V4: o Open Source que está AMEAÇANDO GPT 5.5 e Opus 4.7

Prometeram Renda Universal… mas só veio desemprego?

Mythos Preview: o começo da AGI ou só mais hype?

Ele automatizou TUDO com IA… e pode virar bilionário sozinho


