
Em novembro de 2023, após a OpenAI ter integrado a capacidade do ChatGPT de gerar imagens a partir do DALL-E 3 na interface web do ChatGPT, surgiu um meme efêmero que envolvia usuários pedindo ao modelo que "tornasse isso mais X", onde X poderia ser qualquer coisa.
Um exemplo incluía um homem comum que se tornava cada vez mais "bro". Outro usuário pediu ao ChatGPT para deixar o Papai Noel cada vez mais sério. No entanto, a tendência rapidamente perdeu força, já que as imagens geradas eram bastante similares e pouco interessantes. O fenômeno, embora tenha precedido a definição do termo "AI slop", é academicamente intrigante, pois gerou imagens com resultados cósmicos independentemente da imagem inicial ou do pedido feito.
E se tentássemos uma técnica semelhante com código? O código gerado por LLMs provavelmente não será "slop", pois segue regras rigorosas, ao contrário de saídas criativas como imagens, onde a qualidade pode ser avaliada de forma mais subjetiva. Se o código pode ser aprimorado simplesmente por meio de solicitações iterativas, como pedir ao LLM para "tornar o código melhor" — embora seja um pedido um tanto absurdo — isso representaria um grande aumento de produtividade.
Contudo, o que acontece se você iterar o código em excesso? Qual seria o equivalente a um código se tornando "cósmico"? A única maneira de descobrir é testando!
Apesar de ter pesquisado e desenvolvido ferramentas em torno de LLMs antes do ChatGPT, eu não era fã de utilizar copilotos de código como o GitHub Copilot devido à constante troca de contexto mental entre "oh, o LLM autocompletou meu código, que legal" e "é correto o código gerado pelo LLM?" Isso criava distrações suficientes para que qualquer ganho de produtividade fosse nulo. Além disso, o custo elevado de usar esses LLMs era um fator a ser considerado.
Recentemente, o Claude 3.5 Sonnet me fez repensar essa abordagem. Devido ao que quer que a Anthropic tenha utilizado em seu treinamento, a nova versão do Claude 3.5 Sonnet demonstrou uma adesão incrível aos prompts, especialmente em solicitações de código. Testes de benchmark confirmaram que o Claude superou o GPT-4o em diversas tarefas.
Para este experimento, fornecemos ao Claude 3.5 Sonnet um prompt de codificação em estilo de entrevista usando Python. O desafio era simples e poderia ser implementado por um engenheiro de software novato, mas também poderia ser amplamente otimizado. A intenção era criar um prompt original, não retirado de testes como LeetCode ou HackerRank, para evitar que o LLM usasse respostas memorizadas.
O prompt que criei foi: "Escreva código Python para resolver este problema: Dada uma lista de 1 milhão de inteiros aleatórios entre 1 e 100.000, encontre a diferença entre os menores e maiores números cujos dígitos somam 30."
A implementação gerada foi:
```python
import random
def digit_sum(n):
return sum(int(digit) for digit in str(n))
def find_difference():
numbers = [random.randint(1, 100000) for _ in range(1000000)]
min_num = float('inf')
max_num = float('-inf')
for num in numbers:
if digit_sum(num) == 30:
min_num = min(min_num, num)
max_num = max(max_num, num)
return max_num - min_num if min_num != float('inf') else "No numbers found with digit sum of 30"
```
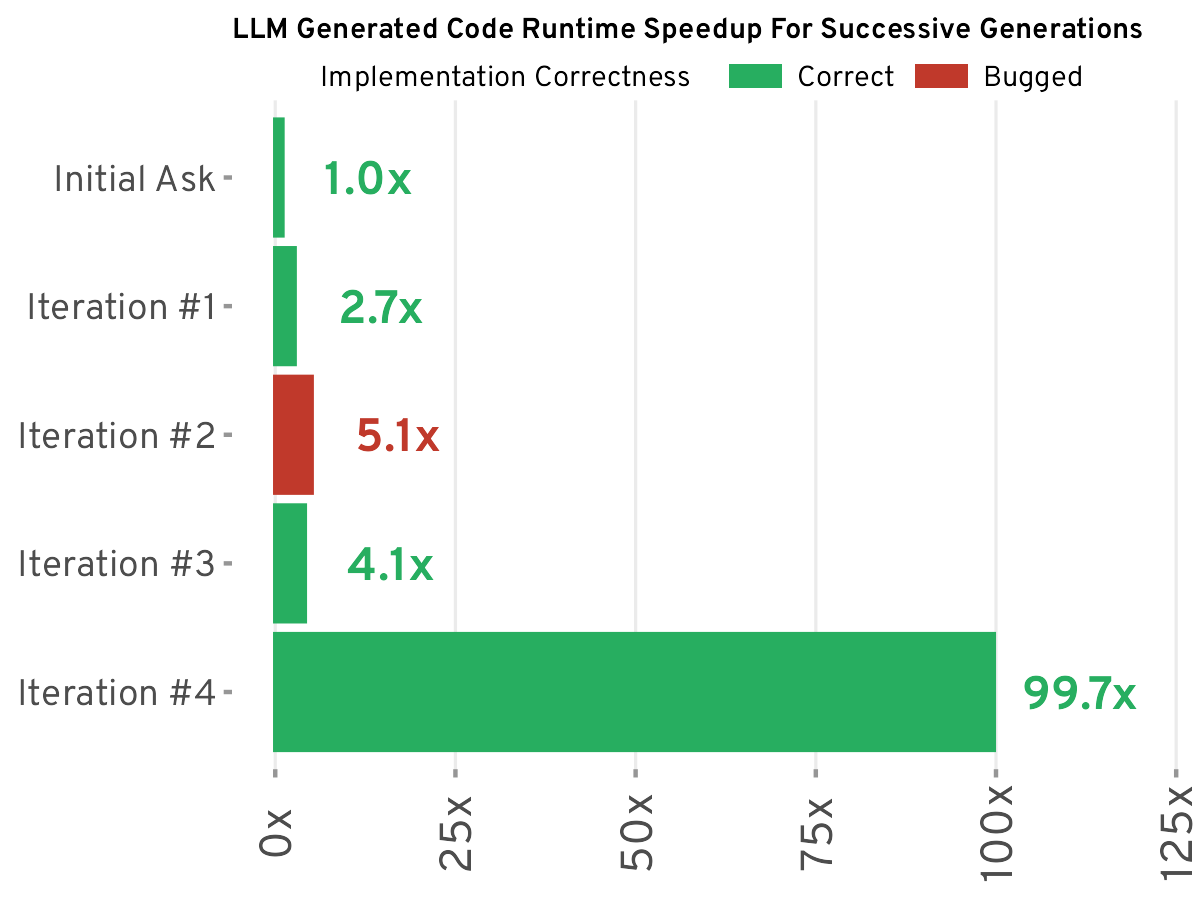
Essa implementação, embora correta, trouxe à tona a curiosidade de muitos programadores sobre otimizações. Por exemplo, a função digit_sum() poderia ser mais eficiente, pois a conversão entre str e int causa sobrecarga desnecessária. No meu MacBook Pro M3, essa execução leva em média 657 milissegundos. Usaremos esse tempo como base para comparações futuras de desempenho.
Ao solicitar ao Claude que melhorasse o código, ele retornou uma versão otimizada que refatorou o código em uma classe Python:
```python
class DigitSumFinder:
def __init__(self, target_sum=30, range_start=1, range_end=100000, count=1000000):
self.target_sum = target_sum
self.range_start = range_start
self.range_end = range_end
self.count = count
self.digit_sums = self._precompute_digit_sums()
def _precompute_digit_sums(self):
digit_sums = array('B', [0] * (self.range_end + 1))
for num in range(self.range_start, self.range_end + 1):
total = 0
n = num
while n:
total += n % 10
n //= 10
digit_sums[num] = total
return digit_sums
def find_difference(self):
min_num = float('inf')
max_num = float('-inf')
count_found = 0
for _ in range(self.count):
num = random.randint(self.range_start, self.range_end)
if self.digit_sums[num] == self.target_sum:
count_found += 1
if num < min_num:
min_num = num
if num > max_num:
max_num = num
return (max_num - min_num, min_num, max_num) if count_found > 0 else (0, None, None)
```
Aqui, o código incluiu melhorias algorítmicas ao evitar a conversão de tipos e pré-computar todas as somas de dígitos, armazenando-as em um array de bytes, acelerando a execução em 2,7x em relação à implementação inicial.
Após outra iteração pedindo "escreva um código melhor", o Claude trouxe uma implementação que alegava ser "ainda mais sofisticada e otimizada". Apesar de alguns avanços, a performance regrediu um pouco, resultando em um código 4,1x mais rápido do que a implementação base.
Conforme as iterações continuaram, o Claude introduziu a biblioteca numba, que pode invocar um compilador JIT, permitindo otimizações de CPU. Ao final, o código se tornava cada vez mais complexo, embora a velocidade de execução chegasse a 6 milissegundos por execução, um aumento de 100x em relação à implementação inicial.
Esses experimentos mostraram que, embora solicitar a um LLM para "melhorar o código" possa resultar em melhorias significativas, a noção de "melhor" é ambígua e pode levar a soluções excessivamente complicadas. A engenharia de prompts se mostrou essencial para guiar o LLM a produzir resultados mais relevantes e eficientes. Através de exemplos e diretrizes claras, os resultados foram ainda mais satisfatórios, indicando que a interação humana continua fundamental para corrigir as falhas inevitáveis nas saídas geradas por LLMs.


Confira os últimos vídeos publicados no canal

A maior virada da Inteligência Artificial começou... e vem da China

o ALERTA de Satya Nadella que ASSUSTOU o mercado de IA

GPT 5.6 SURPREENDE: OpenAI finalmente alcançou a Anthropic?

Os novos modelos de IA estão decepcionando... e ninguém quer admitir isso

Midjourney quer ESCANEAR humanos e o Open Source já rivaliza com Claude Opus

Rio 3.5 e Fable 5: as duas polêmicas que expõem o futuro da IA

Fim dos PCs como conhecemos: Nvidia, Microsoft e IA local vão mudar tudo

O plano SECRETO das Big Techs para cobrar MUITO mais pela IA

BOLHA da IA ou NOVA era de crescimento EXPONENCIAL? O mercado está dividido

Nova IA da OpenAI traduz em TEMPO REAL e pode mudar o mundo dos negócios

Spec Driven Development (SDD): a habilidade que vai separar quem SOBREVIVE à IA

DeepSeek V4: o Open Source que está AMEAÇANDO GPT 5.5 e Opus 4.7

Prometeram Renda Universal… mas só veio desemprego?

Mythos Preview: o começo da AGI ou só mais hype?

Ele automatizou TUDO com IA… e pode virar bilionário sozinho



